
On-Disk Storage Methods (w/ visualizations)
The way you write data can affect your performance.

A few years ago, I gave a talk at Spark Summit 2020 about File Formats about Avro, ORC, and Parquet. I got a bunch of questions about that topic, which I promptly responded to point-to-point, ensuring that the knowledge lives only in those forums… and nowhere else.
That isn’t helpful for most people. This post is my attempt to fix that.
In this series, I’ll lay out some of the primitives of this topic and then dive into the hands on details.
Problem
In the efficiency space - minimizing “work” is key. Whether work requires compute, network, or storage, the goal of efficient data usage is to get the most accurate answer in the fastest and cheapest way possible.
One of the ways the ecosystem has developed to help data practitioners accomplish this task is though the development of File Formats. When you think of a file format, you may think of an extension that looks like .xlsx, .pdf, .pptx… and you’d be right.
Each of these formats tells the “reader” of the format, how to interpret the data that has been written to disk. Similarly, technologies like Parquet, Avro, and ORC help practitioners store their data in a way that minimizes work.
Background / Example Data
The word partition is derived from the Latin Let’s get to the actionable details.
A partition is a logical segment of data. In the big data world, this usually means a piece of a lager dataset. For our purposes, and to illustrate this, I’m going to use the example dataset below.
This dataset has 3 columns (Column A, Column B, and Column C) and 4 rows (Row 0, Row 1, Row 2, and Row 3).

This table should look just like something you’ve seen on Excel, in Pandas, etc.. Let’s take this example a bit further and split up the individual elements into their own logical “pieces.”
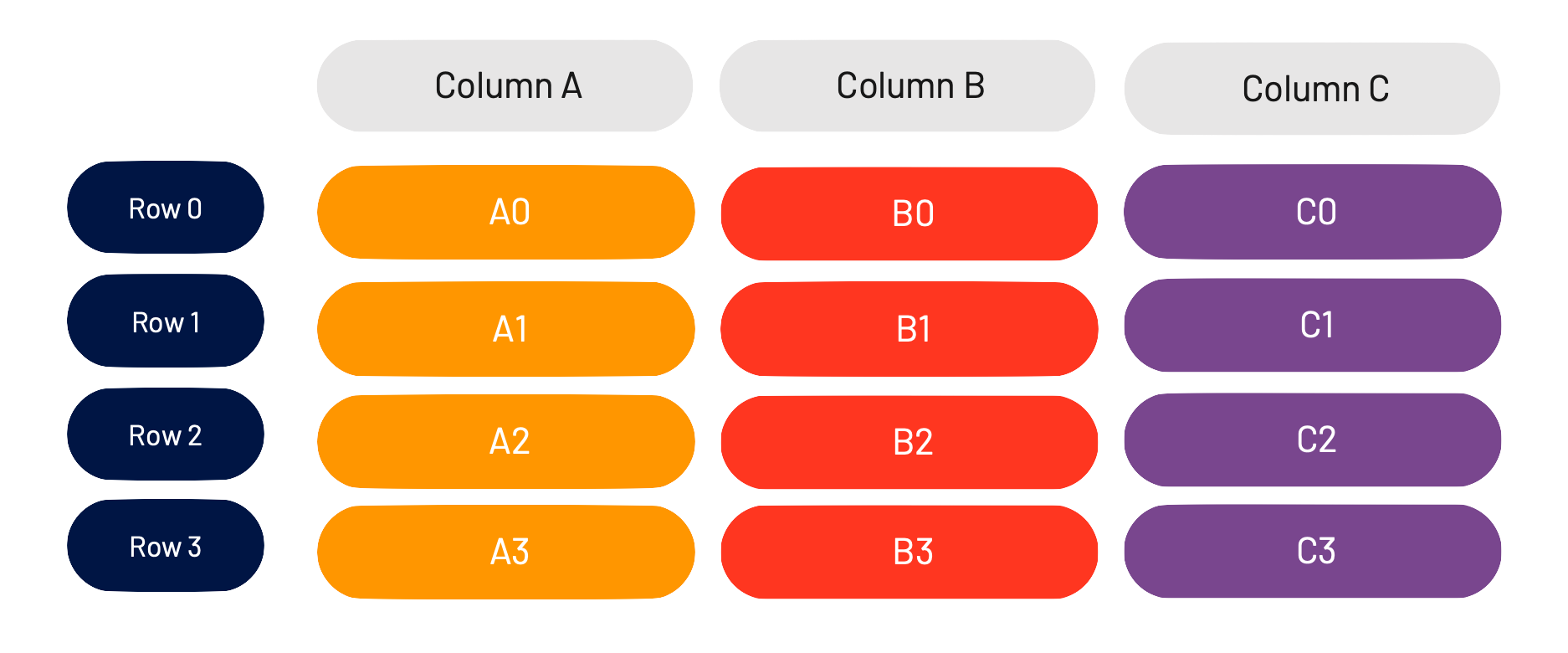
We can refer to each “cell” by it’s “<column><row>.” For example, the second row in Column B is called B1.
Storage
Let’s talk a bit about storage. In the data ecosystem, storage is thought of as cheap (at least cheaper than compute), and as such, few people look into ways of actually optimizing storage.
Storage - in this post - refers to the way that this data is actually stored on disk. Now, whatever represents “disk” may differ from system to system (for example, even though the concept of a disk isn’t exposed to you on S3, there data eventually ends up there).
For this example, and to learn more about partitioning however, I’m going to focus on the most simple storage mechanism - data that is stored on your local hard disk. From there, most everything else can be extrapolated.
Background
Data is stored on hard disks in what is called a block. A block is the minimum amount of data read during any read operation.
I’ve always thought about blocks as a suitcase. When you go on a trip, and have to check in a bag, you pay the same price regardless of how full or empty your suitcase is. That being said, it’s optimal to fill your suitcase with as many objects relevant to your trip as possible, in as easy of a way to find as possible.
Extending this analogy further, packing a bunch of unnecessary stuff in your suitcase isn’t great. Additionally, bringing a ton of suitcases on your trip (unless everything is strictly necessary), also isn’t great. Finally, inside of the suitcase, you want to “group” similar things together - ie. each of a pair of socks should likely be next to each other in the same suitcase, rather than one sock being in one suitcase and one sock being in the other.
In the land of hard drives, all of these insights apply. Reading unnecessary data is expensive. Reading fragmented data is expensive. Random seeks (sock example above) are expensive as well.
Our goal is to lay data out in a manner optimized for our workflows.
Row-wise Storage
In database land, the common way to storage data used to be row-wise. It’s pretty easy to understand why. Most people think about datasets as a list of rows.
Taking our dataset above, let’s store this in a row-wise method.
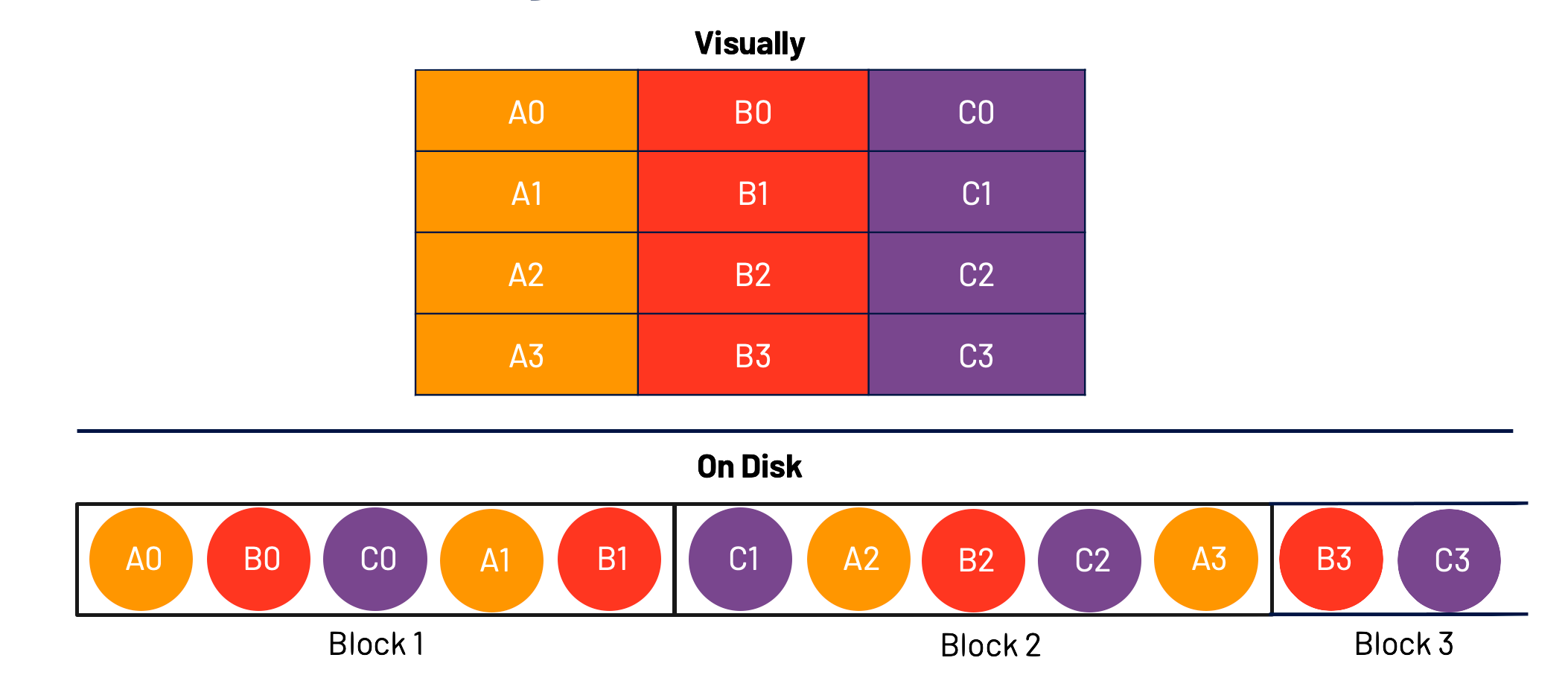
As you can see, I have taken each row in order and packed as much of the rows as I can into a block, before moving to the next block.
This method works great when my goal is to read the data sequentially. All that’s required is a simple linear scan of the block in order. It doesn’t work as well if, for example, I want to only look at Column C. In that case, I’m required to read all of the block (ie. read all of the data) and filter down to Column C.
This is row-wise storage methodology.
Columnar (Column-wise) Storage
Column-wise storage takes the opposite approach and orients around columns.
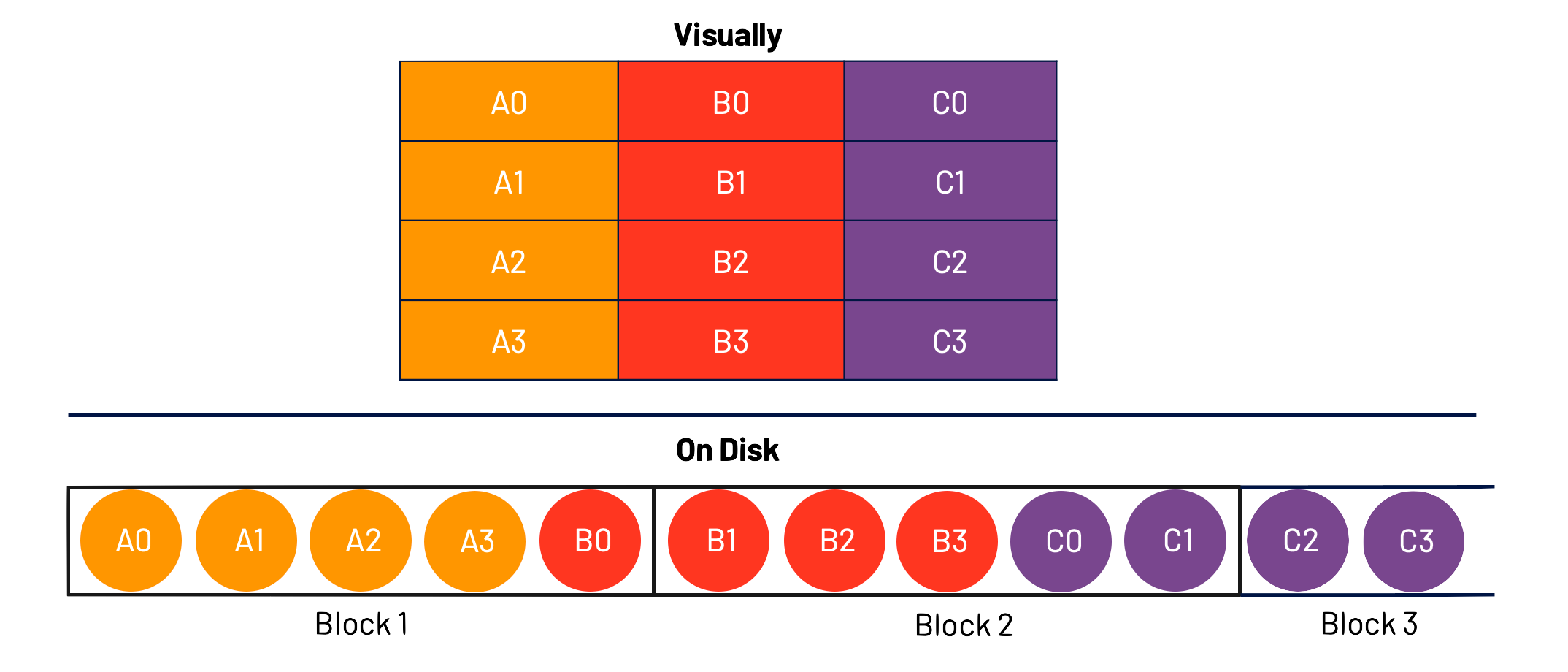
As you can see, we first take the entire column, pack it into a block, and then move onto the next column.
This method works great when the data is read as in a columnar way (ie one column at a time). It doesn’t work well if, if example, I want to reconstruct Row 0. In that situation, I’d need to read all of the data and filter down to the elements that make up Row 0.
Now, we’re in a dilemma - one approach seem too hot favor a row oriented of workflow, one approach seems to cold favor a column oriented workflow. Luckily for us (and Goldilocks), there’s a middle ground.

Hybrid Storage
A hybrid storage model gives us the best of both worlds. First, we group the a fixed number of Rows together and then the further group that by columns. We segment these and call these “Row Groups” (at least in the Parquet terminology)
In this example, we first selected two rows - Row 0 and Row 1. We then, grouped those rows by column, and inserted them into our first Row Group.
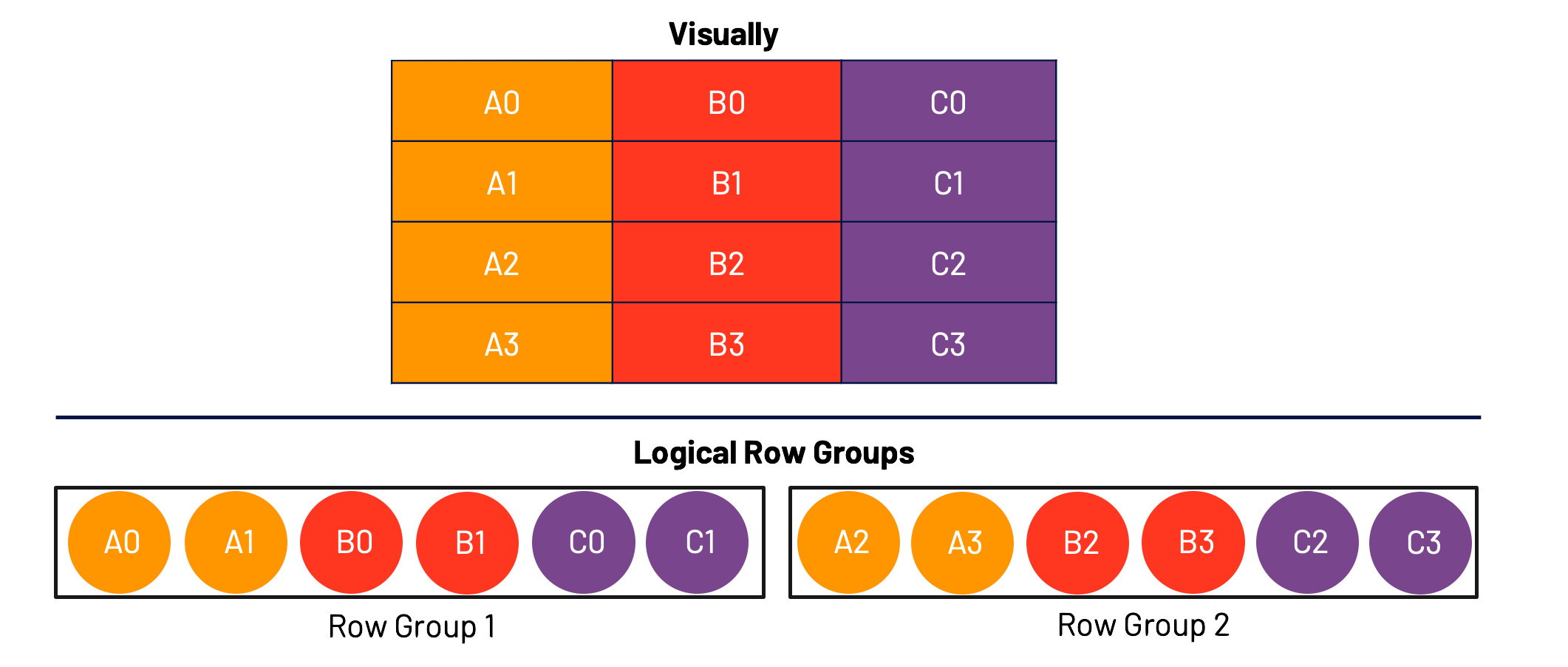
I called these logical Row Groups because this is more of how we should be thinking about them, rather than how they may necessarily end up on disk.
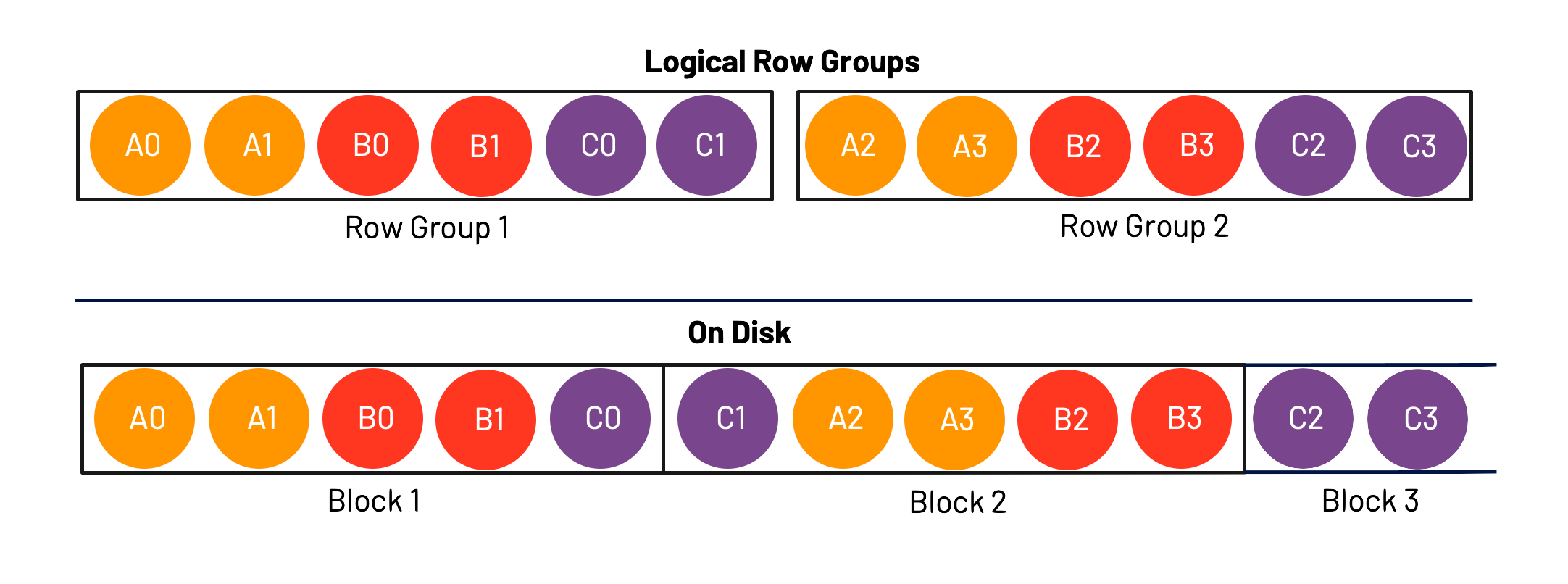
This representation of data is actually immensely powerful. It allows us to both optimize our workflows for row oriented workflows as well as column oriented workflows.
Let’s talk about how this works.
In the case of a row oriented workflow, let’s say I’d want to recreate Row 2. To do this, I would simply need to look at Block 1 and Block 2. If I were operating in a Columnar storage model, I would need to look at Block 1, Block 2, and Block 3. I’ve saved a whole Block!
In the case of a column oriented workflow, let’s say I’d want to recreate Column B. In this case, I would simply need to look at Block 1 and Block 2. If I were operating in a Row-wise storage model, I would need to look at Block 1, Block 2, and Block 3. I’ve once again saved a whole Block!
Our examples used very small data, you can imagine how this extrapolates further with larger data sets.
Data Workflows
Throughout this post, I’d referred to my data workflows as "row oriented” or “column oriented.” Luckily for us, the big data community has come up with some terminology that should help bring these two workflows to life.
OLTP
Online Transaction Processing (OLTP) workloads generally involve larger amounts of short queries/transactions. These tend to be more focused on processing than analytics and as such have more data updates and deleted. Roughly - we can consider OLTP workflows as “row oriented” workflows.
OLAP
Online Analytical Processing (OLAP) workloads are more analysis than processing focused. As such, there tends to be more analytical complexity per query and fewer CRUD transactions. Roughly - we can consider OLAP workflows as “column oriented” workflows.
Conclusion
Using data efficiently, relies on using all levels of the “data stack” (storage, network, compute) efficiently. Reducing the amount of unnecessary data read during a query process can have compounding effects on the speed and efficiency of your analytics process.
Coming soon
In subsequent parts of this series, I’ll be digging more into the details of how everything we have covered thus far can be applied in analytics workloads.
Great article! I really enjoyed the visual approach used to explain on-disk storage concepts. The breakdown of storage formats, blocks, and file organization makes a complex topic much easier to understand, especially for data engineers and database professionals. The discussion around Parquet, ORC, and other storage mechanisms provides valuable insight into how modern analytics platforms optimize performance and storage efficiency. A highly informative read for anyone looking to deepen their understanding of data storage fundamentals and big data architectures.
While this is a nice explanation of row vs columnar file formats and the concept of row-groups, it doesn't really say much about partitioning? Nor does it give any recommendations on how choices like row group size and file size impact cost and efficiency and how to optimize. I really appreciate that you are willing to tackle these complex topics but am also helpful this can go deeper than just simple concept explanations (we have a lot of those already).